
智能语音技术背后的数据壁垒
2020年9月29日,以“机制创新、多方协作、资源共享”为主题的AIIA2020人工智能开发者大会语言智能化与产业应用分论坛在北京市石景山区首钢园北区三高炉隆重召开。

本次大会的分论坛云集了国内外人工智能各领域顶尖学者及知名人物、行业内顶尖企业、知名学者代表、开源社区优秀贡献团队。

作为全球领先的人工智能大数据方案服务商。北京希尔贝壳受邀亮相,CEO 卜辉现场向观众分享了智能语音核心技术的构成以及突破壁垒的方法方案等。
 希尔贝壳CEO--卜辉
希尔贝壳CEO--卜辉
在论坛上,北京希尔贝壳有限公司CEO卜辉,以“智能语音技术背后的数据壁垒”为主题发表演讲,他讲到:“人们从发声到让机器人听懂,需要底层数据的驱动,其中包括了大量的音频的数据和文本数据。”

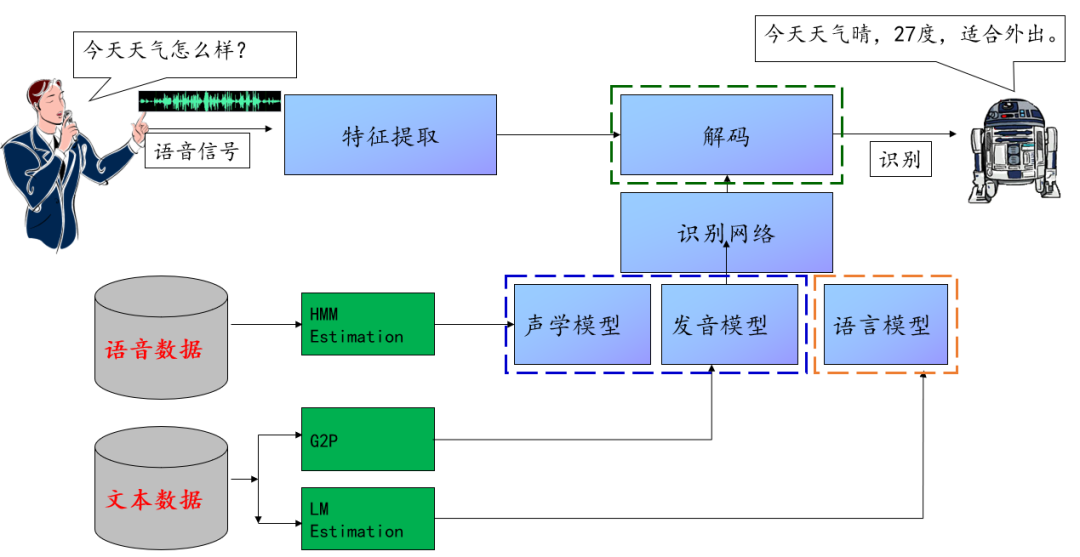 语音识别技术(ASR)
语音识别技术(ASR)
“随着数字人及虚拟现实的技术成熟,人们可以将文字变成音频的输出,主要根据的是高音质语音生成算法、基于GAN的方法、NLP模型的迁移、低频单词的表示。”
 语音合成技术(TTS)
语音合成技术(TTS)
“声纹的目的性很强,在应用到场景上时需要进行声纹的确认Verification、追踪Diarization、辨别Identification,在辨别时还需要通过x-vector、i-vector、D-vector这些算法来实现。”
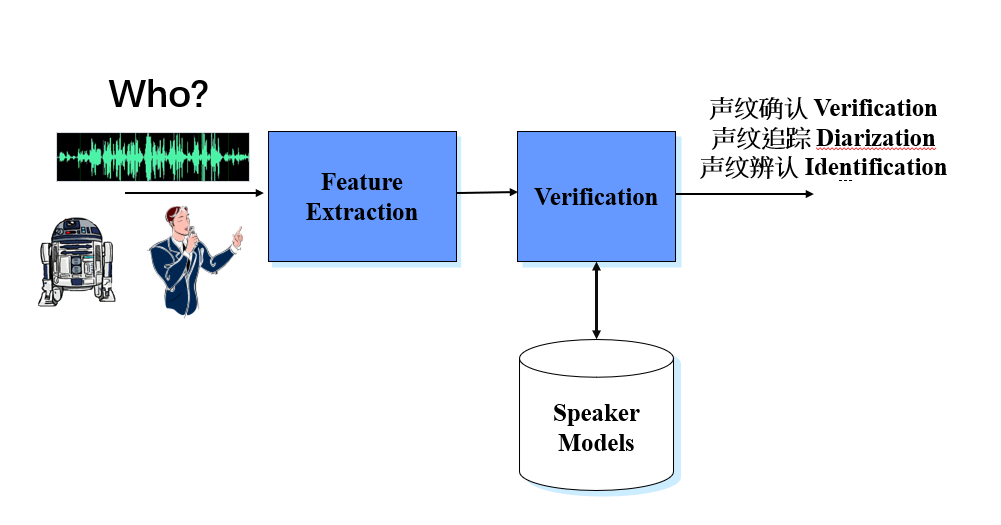
声纹识别技术(VPR)

他在论坛中提出:“这三类技术正是智能语音背后所应用的技术,也正是这三驾马车推动着智能语音的蓬勃发展。在当今AI人工智能当中算法、算力、数据是打开智能语音大门的三把金钥匙,而现如今随着算法和算力的简洁化,数据成为智能语音技术的壁垒。智能语音技术目前还停留在中文普通话的状态,很多方言比如闽南话以及那些口口相传保存下来的语言还有待突破。要想达到机器人从听得见到像人类大脑一样去思考,这还需要语言学家和心理学家等非计算机工作者的支持。”

他表示:“要想突破壁垒就需要从三方向去努力,(1)研发建设不完善的语言数据;(2)结合图像、感知等的数据来形成多模态智能语音数据;(3)开源开放基础数据。”

而后从实例出发,分享了Aishell的建库方案、智能语音数据库制作中的具体落地方案以及研究成果。
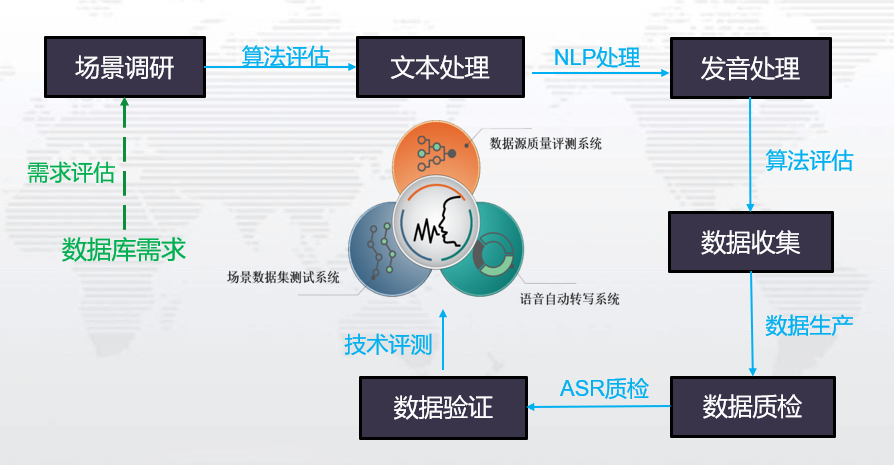
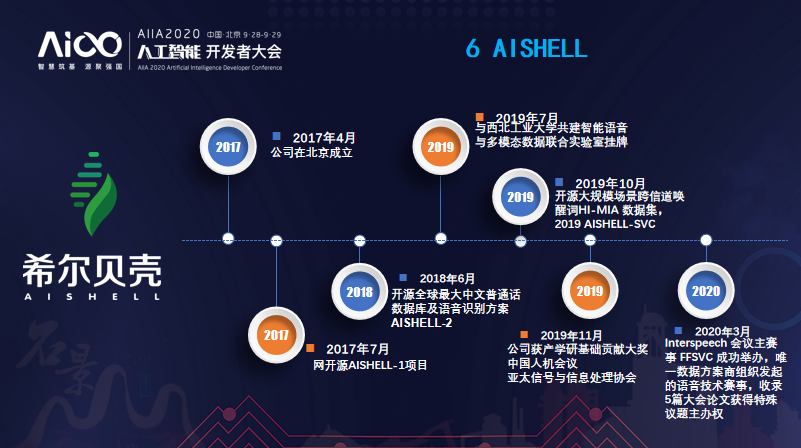
多年来,希尔贝壳不仅通过智能语言数据服务加快了AI在生活中落地的进程,还一直积极进行大规模数据的开源并投身于促进行业发展的学术及行业活动中。未来,希尔贝壳将继续以开放数据、技术变革创新为理念,实现人工智能民主化,让更多的人用到AI技术,更好的服务AI产业。
希尔贝壳,以人工智能民主化为目标

微信公众号
联系我们
商务合作:bd@aishelldata.com
技术服务:tech@aishelldata.com
联系电话:+86-010-80225006
公司地址:
北京市海淀区西北旺东路10号院东区10号楼新兴产业联盟大厦3层316室
开源数据
